In my last post, I showed a bit of code that would take any list, array, diction, or IEnumerable implementer, and return a delimited string.
My solution created a StringBuilder, then looped thru the list, adding the values to the StringBuilder each time. Then, finishing up, remove the last delimiter.
The other solution is to use the LINQ ToArray method, the pass the result to String.Join.
You can see the code for both extension methods below.
1: public static class Extensions
2: {
3: public static string ToDelimitedString<T>(this IEnumerable<T> list, string delimiter, Func<T, string> action)
4: {
5: var sb = new StringBuilder();
6:
7: foreach (T t in list)
8: {
9: sb.Append(action.Invoke(t));
10: sb.Append(delimiter);
11: }
12: sb.Remove(sb.Length - delimiter.Length, 1);
13: return sb.ToString();
14: }
15:
16: public static string ToDelimitedString2<T>(this IEnumerable<T> list, string delimiter, Func<T, string> action)
17: {
18: return string.Join( delimiter, list.Select( action ).ToArray() );
19: }
20:
Next I thought it would be interesting to see what the ToArray was actually doing. ToArray is a Linq function that converts anything that inherits from IEnumerable to an array.
An IEnumerable is a list of undetermined length, and an array has a definite length, so there has to be some sort of reallocation going on. Enter Reflector (now a RedGate product), with Reflector you can select a method and hit Disassemble to inspect the innards. When looking for LINQ methods, you look in the dll System.Core. Below is what you will find.
1: public static TSource[] ToArray<TSource>(this IEnumerable<TSource> source)
2: {
3: if (source == null)
4: {
5: throw Error.ArgumentNull("source");
6: }
7: Buffer<TSource> buffer = new Buffer<TSource>(source);
8: return buffer.ToArray();
9: }
The interesting part is the Buffer class — sorry, struct — which is an internal object. When you start browsing the .Net Framework you will see lots of internal objects running around, some useful, some not. You get used to it.
Anyway, you can see below that Buffer creates an array, then loops though the source object (an IEnumerable of something), adding elements to the array. If the array runs out of space, a new array is created that is double the size of the original array (note that the initial array size is 4). This is standard collection behavior as well, you can look it up in the generic List.
1: internal struct Buffer<TElement>
2: {
3: internal TElement[] items;
4: internal int count;
5: internal Buffer(IEnumerable<TElement> source)
6: {
7: TElement[] array = null;
8: int length = 0;
9: ICollection<TElement> is2 = source as ICollection<TElement>;
10: if (is2 != null)
11: {
12: length = is2.Count;
13: if (length > 0)
14: {
15: array = new TElement[length];
16: is2.CopyTo(array, 0);
17: }
18: }
19: else
20: {
21: foreach (TElement local in source)
22: {
23: if (array == null)
24: {
25: array = new TElement[4];
26: }
27: else if (array.Length == length)
28: {
29: TElement[] destinationArray = new TElement[length * 2];
30: Array.Copy(array, 0, destinationArray, 0, length);
31: array = destinationArray;
32: }
33: array[length] = local;
34: length++;
35: }
36: }
37: this.items = array;
38: this.count = length;
39: }
40:
41: internal TElement[] ToArray()
42: {
43: if (this.count == 0)
44: {
45: return new TElement[0];
46: }
47: if (this.items.Length == this.count)
48: {
49: return this.items;
50: }
51: TElement[] destinationArray = new TElement[this.count];
52: Array.Copy(this.items, 0, destinationArray, 0, this.count);
53: return destinationArray;
54: }
55: }
Now, in spite of the differences between the methods used to return the same results, my initial thought was that there would not be much of a difference, performance wise, in how the code ran. So to test that theory I ran the following tests.
My tests class create a large string list, which is then handed to each method after it is created. I used the same string for every item in the list, because uniqueness didn’t interest me for this test. Plus, it limited the size of the lists I could create. If I used unique strings, the largest list I could create was 8,000,000 before I got out of memory exceptions. Using the same string I could get 20,000,0000.
1: [TestFixture]
2: public class ToDelimitedString_Tests
3: {
4: private List<string> _list;
5:
6: public ToDelimitedString_Tests()
7: {
8: int count = 2500000;
9: _list = new List<string>( count );
10: for (int i = 0; i < count; i++)
11: {
12: _list.Add( "Item" );
13: }
14: }
15:
16: [Test]
17: public void ToDelimitedString_Mine()
18: {
19: string result = _list.ToDelimitedString("----", x=>x);
20: }
21: [Test]
22: public void ToDelimitedString_Theirs()
23: {
24: string result = _list.ToDelimitedString2("----", x=>x);
25: }
26: }
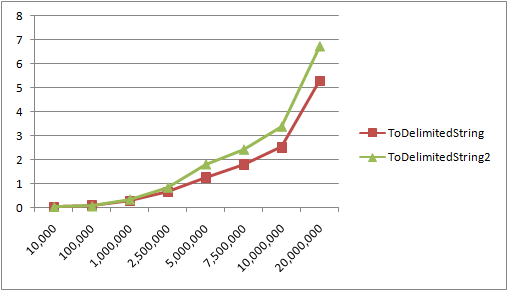
Below you can see the results (charted and in a table) in seconds. Smaller numbers are better.
|
|
ToDelimitedString |
ToDelimitedString2 |
|
10,000 |
0.04 |
0.04 |
|
100,000 |
0.09 |
0.07 |
|
1,000,000 |
0.28 |
0.35 |
|
2,500,000 |
0.65 |
0.85 |
|
5,000,000 |
1.26 |
1.81 |
|
7,500,000 |
1.8 |
2.43 |
|
10,000,000 |
2.52 |
3.38 |
|
20,000,000 |
5.28 |
6.72 |
My conclusion from the data: my hypothesis was correct. There is a performance difference between the two methods, and mine does perform better. Also, as I suspected, there is not a true significant difference between the two methods. At least for the size of the string lists my current application will handle. Note that I had to get up to 1 million items before the times even got interesting, and even then everything happened pretty darn quickly. 10,000 items at 0.04 seconds is pretty darn good. Array sizes below that barely registered.
One interesting note though, I did try to do a profile of the two methods using dotTrace. When profiling the second method was actually faster than mine — consistently. At this point I don’t know why that would be. If you have any ideas please leave me a note.
Thanks for trying this
sb.Remove(sb.Length – delimiter.Length, 1); should still be
sb.Remove(sb.Length – delimiter.Length, delimiter.Length);
Otherwise you only remove the first character of your delimiter.
For most uses it doesn’t matter then but I’ll keep it in mind when I have to use a lot of strings
Well, the way i understand it, the use of buffer that needs to reallocate the size of the array is not unique to the second approach. The stringbuilder also works on an internal array, so to some extent the reallocation process will be a major part of what is taking time in both cases. However there are some factors that influence this and that maybe why your results are not completely conclusive. One major part is how much the array is expanded each time a reallocation occurs, and how many times this happens. Also string.join probably has some “special treatment” in the framework to help performance. Besides that the ToArray and String.Join probably both at the root require these kinds of operations, where your approach only requires reallocation of the array for the stringbuilder.
Anyway, its just my two cents, so now im broke..