
There are plenty of reasons to run L(local)LMs on your own machine, and there are several ways to do it. I have recently become interested in doing so to support a project I am just getting started with and Ollama is a great tool for doing just that.
If you aren’t yet familiar with Ollama, it is a command line tool that enables you to run and work with many different models locally. It gives you the ability to query the models directly from the CLI, but it also provides a web server that hosts a simple API you can code against to query and otherwise work with the models.
Here’s how to get started.
- Install Ollama on your Windows, Mac, or Linux machine. You may also run it in a Docker container if you choose.
- Choose a model to download and run from the models directory. Running a model pulls it down if you don’t have it yet, so this couldn’t be simpler.
- The API is now up and running so you can get started right away.
API endpoints
Here’s a quick listing of the primary endpoints available in the API at the time of this writing. Remember, you are working within the context of the Ollama server, so these operations refer to Ollama’s complete set of functionality, not just to interacting with models.
- POST /api/generate
- POST /api/chat
- POST /api/create
- GET /api/tags
- POST /api/show
- POST /api/copy
- DELETE /api/delete
- POST /api/pull
- POST /api/push
- POST /api/embed
- POST /api/embeddings
- GET /api/ps
The rest of this article focuses on the chat endpoint, because that’s what I am primarily using in my project.
Working with the API
The API has decent documentation here, but I’ll walk through a quick start on how to interact with it for chat purposes. Also, I’ve been using TypeScript in my project, so that’s what I’ll use in the following examples. I think it’s a readable enough language for most of us.
Here is the entire script that I use to generate a chat response and pull the code from the response using the Phi3 small language model from Microsoft. There are some things to tease apart in the code which I’ll cover after the script snippet.
import axios from 'axios';
const baseApiUrl = "http://localhost:11434/api";
const chatEndpoint = baseApiUrl + "/chat";
const modelName = "phi3:latest";
const chatQueryData = JSON.stringify({
"model": modelName,
"messages": [
{
"role": "user",
"content": "Show how to reverse a string in C#"
}
],
"stream": false,
"format": "json"
});
callRestAPI(chatEndpoint, 'POST', chatQueryData)
.then((reply) => showResponse(reply));
function showResponse(data: any) {
let answerString = data.message.content;
let answer = JSON.parse(answerString).code;
console.log(answer);
}
async function callRestAPI(url: string, method: 'GET' | 'POST' | 'PUT' | 'DELETE', data?: any) {
try {
const response = await axios({
method,
url,
data,
headers: {
'Content-Type': 'application/json'
}
});
return response.data;
} catch (error) {
console.error(error);
}
}Parsing the response
You may already have noticed that I am asking a code question. In my case, all I am interested in is the exact code returned by the query. Part of the JSON response (too big to show it all) looks like this:
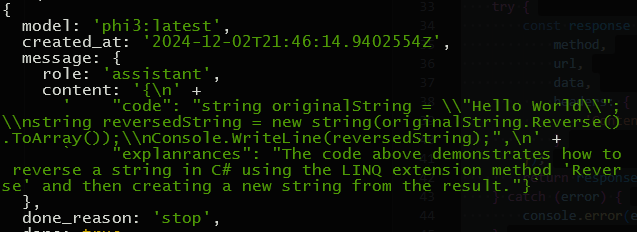
Note the message section has a content property I can work with. The value of content is a simple string, but looking closely you can see it is itself embedded JSON.
Once that string is turned into JSON it looks like this:

The code property is the one we are after and as you can see in the full script above we extract the code like so:
let answer = JSON.parse(answerString).code;This gives me exactly what I was after, which is just the code sample provide by the model in its response.
Conclusion
This was a very specific solution to a specific problem, but you can see there are a lot more features of the API I haven’t covered. These API capabilities have been just as easy for me to consume as the /chat endpoint and I am still working my way through the rest of the API.
If you have a use case for talking to models on your local machine, Ollama may be the answer. Not only can you try different models to assess their effectiveness for your use case, but you can build complete solutions that run local to your machine.
There are other ways to host models locally but this has been a great start for me. Good luck on your project!